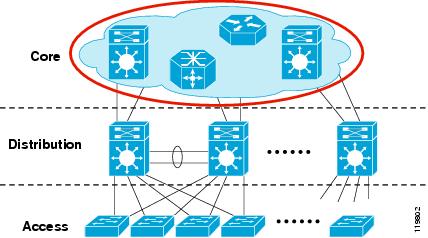
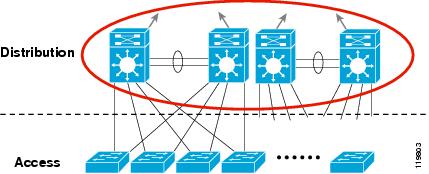
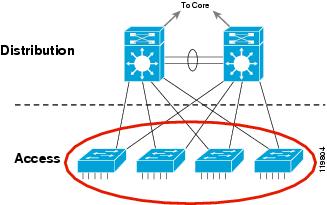
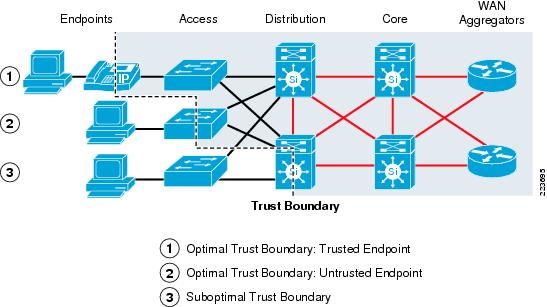
Brief explanation about Optical Transport Technologies:
FDM
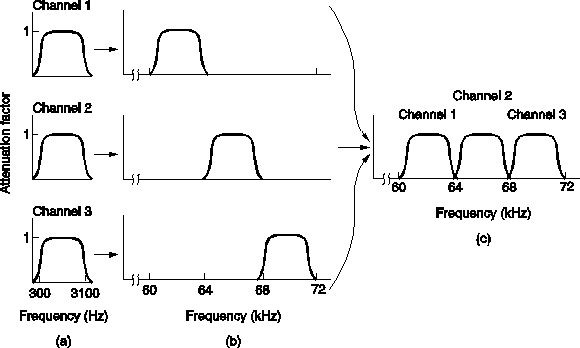
Frequency-Division Multiplexing (FDM) is a form of signal multiplexing which involves assigning non-overlapping frequency ranges to different signals or to each "user" of a medium.
TDM and PDH
Time-Division Multiplexing (TDM) is a type of digital (or rarely analog) multiplexing in which two or more bit streams or signals are transferred apparently simultaneously as sub-channels in one communication channel, but are physically taking turns on the channel. The time domain is divided into several recurrent timeslots of fixed length, one for each sub-channel. A sample byte or data block of sub-channel 1 is transmitted during timeslot 1, sub-channel 2 during timeslot 2, etc. One TDM frame consists of one timeslot per sub-channel plus a synchronization channel and sometimes error correction channel before the synchronization. After the last sub-channel, error correction, and synchronization, the cycle starts all over again with a new frame, starting with the second sample, byte or data block from sub-channel 1, etc.

The Plesiochronous Digital Hierarchy (PDH) system, also known as the PCM system, for digital transmission of several telephone calls over the same four-wire copper cable (T-carrier or E-carrier) or fiber cable in the circuit switched digital telephone network.
The PDH system effectively develops the idea of primary multiplexing using time
Division Multiplexing (TDM) to generate faster signals. This is done in stages by first combining (multiplexing) E1 or T1 links into what are known as E2 or T2 links, and if required, going even further by combining (multiplexing) E2 or T2 links, etc.
This multiplexing hierarchy is known as the Plesiochronous Digital Hierarchy (PDH). Plesiochronous, meaning “almost synchronous,” relates to the inputs that can be of slightly varying speeds relative to each other and the system’s ability to cope with the differences.
These groups of signals can be transmitted as an electrical signal over a coaxial cable, as radio signals, or optically via fiber-optic systems. As such, PDH formed the backbone of early optical networks.
The aggregate signal can be sent to line at any stage of the hierarchy, using the appropriate transmission medium and modulation techniques.
The big issue with this multiplexing technology is to drop or add 2Mbps interfae (another E1) to the ring need to implement the equipments all the way down from the ~140Mbps to the 2M multiplexer.
Line rates:
SDH-SONET
Synchronous Optical Networking (SONET) and Synchronous Digital Hierarchy (SDH) are standardized
multiplexing protocols that transfer multiple
digital bit streams over
optical fiber using
lasers or highly coherent light from
light-emitting diodes (LEDs). At low transmission rates data can also be transferred via an electrical interface. The method was developed to replace the
Plesiochronous Digital Hierarchy (PDH) system for transporting large amounts of
telephone calls and
data traffic over the same fiber without synchronization problems.
Both SDH and SONET are widely used today: SONET in the
United States and
Canada, and SDH in the rest of the world. Although the SONET standards were developed before SDH, it is considered a variation of SDH because of SDH's greater worldwide market penetration.
NG-SDH/SONET
SONET/SDH development was originally driven by the need to transport multiple PDH signals—like DS1, E1, DS3, and E3—along with other groups of multiplexed 64 kbit/s
pulse-code modulated voice traffic. The ability to transport ATM traffic was another early application. In order to support large ATM bandwidths, concatenation was developed, whereby smaller multiplexing containers (e.g., STS-1=STS-3C/3=52Mbps (also named STM-0)) are inversely multiplexed to build up a larger container (e.g., STS-3c) to support large data-oriented pipes.
Basically Next Generation SDH should helps us to send Ethernet traffic in more efficient way over the SDH/SONET technology.
One problem with traditional concatenation, however, is inflexibility. Depending on the data and voice traffic mix that must be carried, there can be a large amount of unused bandwidth left over, due to the fixed sizes of concatenated containers. For example, fitting a 100 Mbit/s
Fast Ethernet connection inside a 155 Mbit/s STS-3c container leads to considerable waste. More important is the need for all intermediate network elements to support newly-introduced concatenation sizes. This problem was overcome with the introduction of Virtual Concatenation.
Virtual concatenation (VCAT) allows for a more arbitrary assembly of lower-order multiplexing containers, building larger containers of fairly arbitrary size (e.g., 100 Mbit/s) without the need for intermediate network elements to support this particular form of concatenation. Virtual concatenation leverages the
X.86 or
Generic Framing Procedure (GFP) protocols in order to map payloads of arbitrary bandwidth into the virtually-concatenated container.
The Link Capacity Adjustment Scheme (
LCAS) allows for dynamically changing the bandwidth via dynamic virtual concatenation, multiplexing containers based on the short-term bandwidth needs in the network.
MSPP
Multi-Service Provisioning Platform, MSPPs enable service providers to offer customers new bundled services at the transport, switching and routing layers of the network, and they dramatically decrease the time it takes to provision new services while improving the flexibility of adding, migrating or removing customers.
These provisioning platforms allow service providers to simplify their edge networks by consolidating the number of separate boxes needed to provide intelligent optical access. They drastically improve the efficiency of SONET networks for transporting multiservice traffic.
The platforms also reduce the number of network management systems needed, and decrease the resources needed to install, provision and maintain the network.
MSPPs are very complex systems, involving a variety of hardware and software technologies, millions of lines of code and a range of functionality. Each vendor's approach is unique and optimized to solve a specific set of problems.
Because MSPPs are close to the customer, they must interface with a variety of customer premises equipment and handle a range of physical interfaces. Most vendors support telephony interfaces (DS-1, DS-3), optical interfaces (OC-3, OC-12), and Ethernet interfaces (10/100Base-T). DSL and Gigabit Ethernet interfaces may also be offered.
MSPP offers SDH services E-LAN and Multipoint to Multipoint.
WDM
Early fiber optic transmission systems put information onto strands of glass through simple pulses of light. A light was flashed on and off to represent the “ones” and “zeros” of digital information. The actual light could be of almost any wavelength (also known as color or frequency) from roughly 670nm to 1550nm.
During the 1980s, fiber optic data communications modems used low-cost LEDs to put near-infrared pulses onto low-cost fiber. As the need for information increased, the need for bandwidth also increased. Early SONET systems used 1310nm lasers to deliver 155 Mb/s data streams over very long distances. But this capacity was quickly exhausted. Advances in optoelectronic components allowed design of systems that simultaneously transmitted multiple wavelengths of light over a single fiber. Multiple high-bit rate data streams of 2.5 Gb/s, 10 Gb/s and, more recently, 40 Gb/s and 100Gb/s could be multiplexed through divisions of several wavelengths. And so was born Wavelength Division Multiplexing (WDM).
In fiber-optic communications, wavelength-division multiplexing (WDM) is a technology which multiplexes a number of optical carrier signals onto a single optical fiber by using different wavelengths (i.e colours) of laser light. This technique enables bidirectional communications over one strand of fiber, as well as multiplication of capacity.
The term wavelength-division multiplexing is commonly applied to an optical carrier (which is typically described by its wavelength), whereas frequency-division multiplexing typically applies to a radio carrier (which is more often described by frequency). Since wavelength and frequency are tied together through a simple directly inverse relationship, the two terms actually describe the same concept.
DWDM and CWDM
CWDM - Coarse Wavelength Division Multiplexing. WDM systems with fewer than eight active wavelengths per fiber.
DWDM - Dense Wavelength Division Multiplexing. WDM systems with more than eight active wavelengths per fiber.
Types of WDM
Currently, there are two types of WDM in existence today: Coarse WDM (CWDM) and Dense
WDM (DWDM). Backwards as it may seem, DWDM came well before CWDM, which appeared only after a booming telecommunications market drove prices to affordable lows. Whereas CWDM breaks the spectrum into big chunks, DWDM dices it finely. DWDM fits 40-plus channels into the same frequency range used for two CWDM channels.
CWDM is defined by wavelengths. DWDM is defined in terms of frequencies. DWDM’s tighter wavelength spacing fit more channels onto a single fiber, but cost more to implement and operate.
Distinctive CWDM differences
CWDM can—in principle—match the basic capabilities of DWDM but at lower capacity and lower cost. CWDM enables carriers to respond flexibly to diverse customer needs in metropolitan regions where fiber may be at a premium. However, it’s not really in competition with DWDM as both fulfill distinct roles that largely depend upon carrier-specific circumstances and requirements anyway. The point and purpose of CWDM is short-range communications. It uses wide-range frequencies and spreads wavelengths far apart from each other. Standardized channel spacing permits room for wavelength drift as lasers heat up and cool down during operation. By design, CWDM equipment is compact and cost-effective as compared to DWDM designs.
Distinctive DWDM differences
DWDM is designed for long-haul transmission where wavelengths are packed tightly together. Vendors have found various techniques for cramming 32, 64, or 128 wavelengths into a fiber. When boosted by Erbium Doped-Fiber Amplifiers (EDFAs)—a sort of performance enhancer for high-speed communications—these systems can work over thousands of kilometers. Densely packed channels aren’t without their limitations. First, high-precision filters are required to peel away one specific wavelength without interfering with neighboring wavelengths. Those don’t come cheap. Second, precision lasers must keep channels exactly on target. That nearly always means such lasers must operate at a constant temperature. High-precision, high-stability lasers are expensive, as are related cooling systems.
OTN
ITU-T Recommendation
G.709 is commonly called Optical Transport Network (OTN) (also called digital wrapper technology or optical channel wrapper). As of December 2009 OTN has standardized the following line rates.
- OTU0 is currently under development to transport a 1 GbE signal.
- OTU1 has a line rate of approximately 2.7 Gbit/s and was designed to transport a SONETOC-48 or synchronous digital hierarchy (SDH) STM-16 signal.
- OTU2 has a line rate of approximately 10.7 Gbit/s and was designed to transport an OC-192, STM-64 or 10Gbit/s WAN. OTU2 can be overclocked (non standard) to carry signals faster than STM64/OC192 (9.953 Gbit/s) like 10 gigabit Ethernet LAN PHY coming from IP/Ethernet switches and routers at full line rate (10.3 Gbit/s). This is specified in G.Sup43 and called OTU2e.
- OTU3 has a line rate of approximately 43 Gbit/s and was designed to transport an OC-768or STM-256 signal.[2]
- OTU4 has a line rate of approximately 112 Gbit/s and was designed to transport a 100 Gigabit Ethernet signal.
ASON
ASON (Automatically Switched Optical Network) is a concept for the evolution of transport networks which allows for dynamic policy-driven control of an optical or SDH network based on signaling between a user and components of the network. [1] Its aim is to automate the resource and connection management within the network. The IETF defines ASON as an alternative/supplement to NMS based connection management

While
ITU has worked on the requirements and architecture of ASON based on the requirements on its members, it is explicitly aiming to avoid the development of new protocols, when existing ones will work fine. The
IETF, on the other hand, has been tasked with the development of new protocols in response to general industry requirement. Therefore, while ITU already include the
PNNI protocol for signaling in the Control plane, IETF has been developing
GMPLS as a second option protocol to be used in the Control Plane for signalling. As a product of IETF,
GMPLS (Generalized
MPLS) uses
IP to communicate between different components in the Control Plane.
Thats it... (sponsored by Wiki..)